数据仓库概念介绍
文章目录
【注意】最后更新于 January 1, 0001,文中内容可能已过时,请谨慎使用。
为什么需要数据仓库
如果直接从业务数据库取数据会有如下几个问题
- 结构复杂
- 数据杂乱(不同的数据库针对相同的业务可能会有不同的命名,处理方式)
- 理解困难(业务数据会存在一些特殊字段用于方便开发)
- 缺少历史数据
发展
数据仓库的趋势:
实时数据仓库以满足实时化&自动化决策需求;大数据&数据湖以支持大量&复杂数据类型(文本、图像、视频、音频)
元数据
元数据指定了数据仓库数据的来源,价值,用法和特点,并定义了在每个体系结构层如何更改和处理数据
数据元数据包含
- 文件标识符
- 进入数据仓库的日期
- 文件描述
- 文件来源
- 文件来源的日期
- 文件的分类
- 清理日期
数据仓库元数据包含
- 数据仓库的表结构
- 数据仓库的表属性
- 数据仓库的源数据来源
- 从业务系统到数据仓库的映射
- 数据模型的说明
- 抽取日志
- 数据的定义和描述
- 数据单元之间的关系
数仓分层
数据仓库从模型层面分为三层:
ODS,操作数据层,保存原始数据 DWD,数据仓库明细层,根据主题定义好事实与维度表,保存最细粒度的事实数据 DM,数据集市/轻度汇总层,在DWD层的基础之上根据不同的业务需求做轻度汇总
维度建模
维度建模是一种将数据结构化的逻辑设计方法维度模型由一系列含有数值型度量的事实表组成,而事实表中的数值型度量则被一系列带有文本形式上下文的维度表所环绕
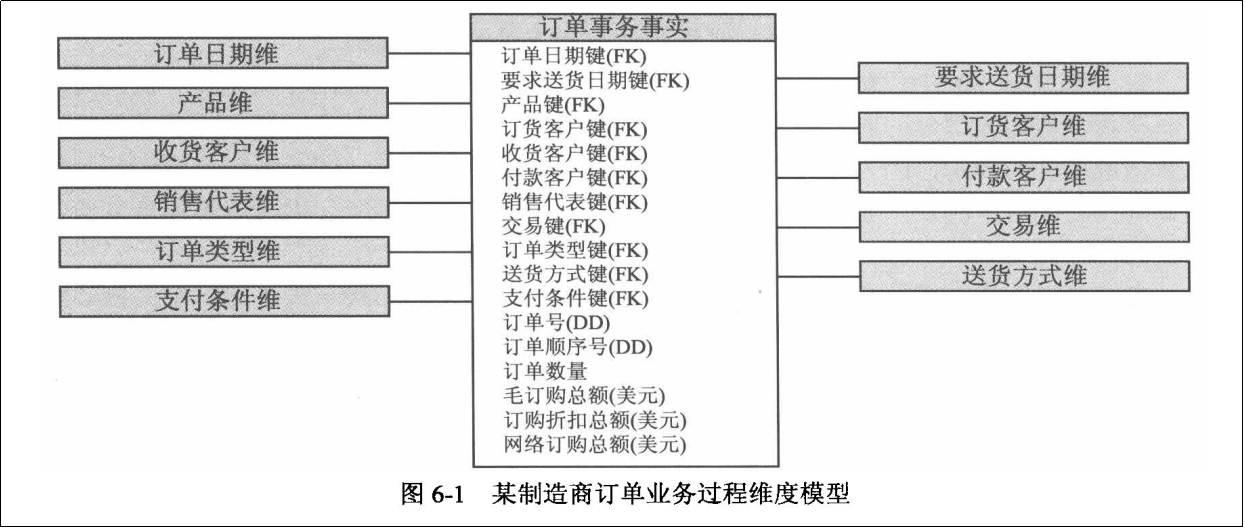
维度
维度属性
代表维度和描述它们其它可能属性例如产品由它的类型,所属类别,品牌,销售部门描述
退化维
退化维通常在事实表中,比如订单号,本身即是维度也是事实,为其创建单独的维度没有意义
层次结构
维度通常是有层次的,用于分析时候钻取和切片
案例:假如有一个交易订单,创建事实表。现在统计2019年”双11“的下单GMV,得到一行记录;沿着层次向下钻取,继续沿着层次向下钻取,添加行业,得到行业实例个数的记录数;继续沿着层次向下钻取,添加一级类目,得到一级类目实例个数的记录数。可以看到,通过向报表中添加连续的维度细节级别。实现在层次结构中进行钻取
-
如何处理层次结构
- 固定层次
- 使用桥接表
- 使用导航表(树形查询)
使用桥接表的方案,同时使加权查询得到支持
杂项维度
杂项维度就是一种包含的数据具有很少可能值的维度。事务型商业过程通常产生一系列混杂的、低基数的标志位或状态信息。与其为每个标志或属性定义不同的维度,不如建立单独的将不同维度合并到一起的杂项维度。这些维度,通常在一个模式中标记为事务型概要维度,一般不需要所有属性可能值得笛卡尔积,但应该至少包含实际发生在源数据中得组合值。例如,在销售订单中,可能存在很多离散数据(yes-no这种开关类型得值),如:(1)verification_ind(如果订单已经被审核,值为yes) (2)credit_check_flag (表示此订单的客户信用状态是否已经检查)(3)new_customer_ind(如果这是新客户的首个订单,值为yes)(4)web_order_flag(表示一个订单是在线上订单还是线下订单) 这类数据通常用于增强销售分析,其特点是属性可能值很少。在建模复杂的操作源系统时,经常会遭遇大量五花八门的标志或者状态信息,他们包含小范围的离散值。处理这些较低基数的标志或者状态位可以采用以下几种方法
事实
每个事实描述企业发生的一类事,不同的业务对应的事实不同
比如电商的订单就是一个事实
度量
度量是事实的一个数值特征
比如订单的金额
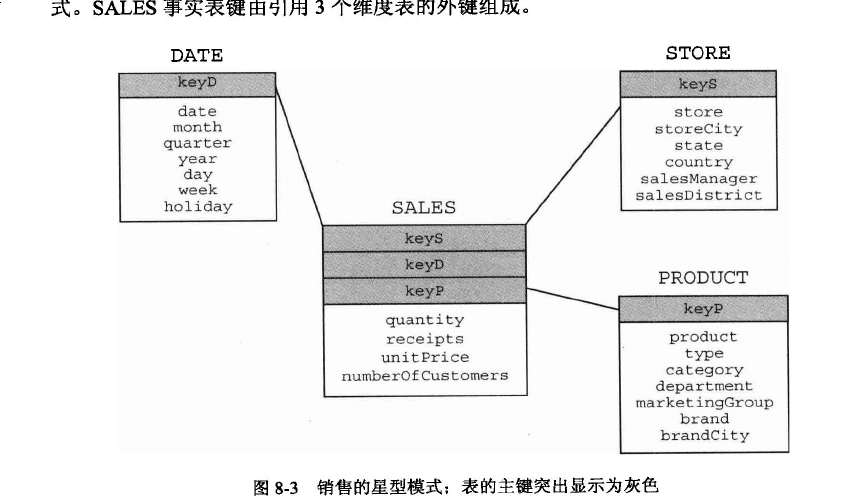
星型模型
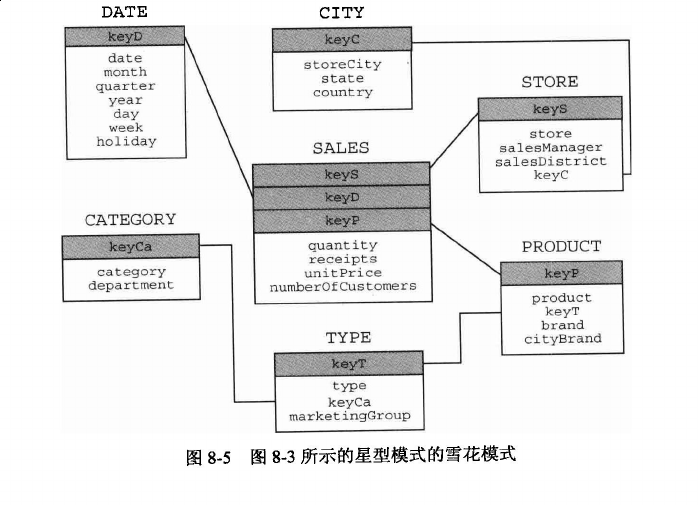
雪花模型
将星状的维度表拆分为更小的表
建模的流程
-
选择业务过程
-
声明粒度
-
识别维度
-
识别事实
文章作者 lialzm
上次更新 0001-01-01